On AI Inversion Attacks
iCTF
Recently, I competed in iCTF with several friends, as I was told there would be interesting and fun challenges. I was not disappointed!
The 2024 iCTF is sponsored by the ACTION NSF AI Institute, and was organized by Shellphish and the UCSB Women in Computer Science group.
One of these challenges was called linear-labyrinth.
linear-labyrinth
Un-neurals your network :3
Made by 0xk4l1
The creator, 0xk4l1, is a friend of mine. We have worked together before, so I was excited about trying her challenge!
The challenge consisted of 4 files - chal.py, model.py, out.png, and model.pth.
chal.py read in a flag.png file, converted it to a tensor, and then passed it through a model. The model was defined in model.py, and the output was saved as out.png. The model.pth file contained the state dictionary for the model. We also had some weird dimensions - 17x133 pixels.
import torch
import numpy as np
import cv2
from model import Model
flag = cv2.imread('flag.png', 0)
tensor = torch.from_numpy(flag).to(torch.float32)
model = Model()
out_tensor = model(tensor)
out_arr = out_tensor.detach().numpy()
cv2.imwrite('out.png', out_arr)
#save model
torch.save(model.state_dict(), 'model.pth')model.py performed two linear transformations on the input tensor. Pretty self-explanatory.
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(133, 133)
self.linear2 = torch.nn.Linear(133, 133)
def forward(self, x):
x = self.linear1(x)
x = self.linear2(x)
return xThe out.png file was a file filled with what looked like static, and our model.pth stored the PyTorch state dictionary for the Model (also contained the weight and bias of our model).
Step 1 - Initial Thoughts
After downloading the file, my first step was to look at what model.py did. chal.py contained the process for converting our flag.png into out.png, but model.py contianed the process by which it did that. I saw that we were performing torch.nn.Linear(133, 133) twice on the input image, so my first step was to look deeply into this process.
Step 2 - torch.nn.linear()
As per the documentation, Linear() performs a Applies an affine linear transformation to the input data with the equation y = xA^T + b. 133, in this case, defined the input and the output of the transformation. Considering that our output image was 17x133 pixels, this was interesting.
The following resources gave me some additional information as I researched this, allowing me to improve my understanding of nn.Linear()
Pytorch Documentation on torch.nn.Linear
Python Linear() code
Linear C++ implementation - this is where the code actually does things!
Introduction to nn.Linear in PyTorch: Clearly Explained
Step 3 - Reversing the process
My first step was reversing the process on a test image, to sanity check that the process did what I thought it did, and do figure out a method to reverse the steps to create a solve script. I used an image of 17x133 pixels, which stored a text that said ictf{this-is-fake}.
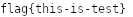
Then, I looked into .pth files, and specifically, model.pth.
Model.pth stores each step that was performed on the input, in addition to the steps, weights, and biases that were introduced in our linear affine transformation. Cool, I can obtain this information by initializing a new Model(), loading the state dictionary by doing model.load_state_dict(torch.load('model.pth')), and then getting the list of steps by calling list(model.children()).
Step 4 - Reversing Model()
To reverse our model, we can perform the following steps in our python code. z, in this case, would represent our tensor converted to a numpy array. I then reversed the process that nn.Linear() performs at each step of the function, which required going into the pytorch
steps = reversed(list(model.children())) # reverse the order of the layers
for step in steps: # For each layer in the model
z = z - step.bias # Subtract the bias from the tensor
z = z[..., None] # Add a new axis to the tensor
z = torch.linalg.pinv(step.weight) @ z # Multiply the tensor by the inverse of the weight matrix
z = torch.squeeze(z) # Remove the new axis from the tensorStep 5 - Back and forth
Knowing this, I set up a test script which performed the proces in chal.py, and then reversed it, to verify that I had a good comprehension of what was going on.
import torch
import numpy as np
import cv2
from model import Model
model = Model()
model.load_state_dict(torch.load('model.pth'))
# Read in the output image, keep in mind we saved a float32 image
flag = cv2.imread('testing_input.png', 0)
steps = list(model.children())
tensor = torch.from_numpy(flag).to(torch.float32)
for step in steps:
tensor = step(tensor)
out_arr = tensor.detach().numpy()
cv2.imwrite('out.png', out_arr)
out = cv2.imread('out.png', 0)
print('Out shape:', out.shape)
print('Out dtype:', out.dtype)
print('Out Contents:', out)
z = torch.from_numpy(out_arr).to(torch.float32) # out_arr is not equal to out
# reversed_steps = list(model.children())[::-1]
steps = reversed(list(model.children())) # reverse the order of the layers
for step in steps: # For each layer in the model
z = z - step.bias # Subtract the bias from the tensor
z = z[..., None] # Add a new axis to the tensor
z = torch.linalg.pinv(step.weight) @ z # Multiply the tensor by the inverse of the weight matrix
z = torch.squeeze(z) # Remove the new axis from the tensor
# print('Agreement between the two snippets:', torch.dist(out_tensor, z))
# Reconstruct the image
reconstructed_arr = z.detach().numpy()
# Convert all values to integers
# Write the array to a text file containing the contents of reconstructed_arr
np.savetxt('reconstructed_arr.txt', reconstructed_arr, fmt='%d')
cv2.imwrite('testing2.png', reconstructed_arr)This worked! Not fully, though.
You’ll notice that in my code, specifically z = torch.from_numpy(out_arr).to(torch.float32), I work with out_arr, and not out.
This is because I was having trouble performing this on out, which was read in by opencv. I could perform the reverse process perfectly on out_arr, but when I read out.png back in, I lose several values!
After some research, I found that this was because opencv imwrite actually loses float32 values on a write. Specifically, “With PNG encoder, 8-bit unsigned (CV_8U) and 16-bit unsigned (CV_16U) images can be saved.”. However, we’re working with float32 values. Ugh. There goes my perfect script
Step 6 - Inversion Attacks
So, my perfect script doesn’t work. And this challenge has solves, which means that either
- We are working with a png file that doesn’t contain an image at all, and rather a bunch of integers stored as a .png,
OR - We need to perform another style of attack
The first was easy to verify by some modification of my initial solve script, and I didn’t see much luck. So, I needed to look at other attacks. My first thought was performing an inversion attack. Inversion is the process of inverting a model in order to get a lossy representation of the training data. We get a lossy representation, most of the time we run this attack on models, because a model can be viewed as a lossy compression algorithm. Most models contain only a portion of the training data, and this type of attack is actually really difficult to execute in practice.
We can also use the adversarial robustness toolbox (ART) to perform this attack, but in this case, I just reused a previous manual MIFace attack I had performed before.
Interlude - MIFace Attack
Fredrikson et al. developed the MIFace to demonstrate attacks against face recognition models. However, it is usable in this challenge. This attack works best for models in which examples in each class look similar to each other. I thought this would be applicable here. I later learn that there is a much better solution.
A high level overview of our attack is that we’ll iterate through the space of images, starting with a randomized image that is similar to out.png in size. We then use stochastic gradient descent to optimize that test image to generate an image that matches the class (hint: I forgot to clamp pixels within acceptable ranges, which made this challenge a lot hard than it should have been).
Step 7 - My attack
import torch
import numpy as np
import cv2
from model import Model
import matplotlib.pyplot as plt
from art.estimators.classification import PyTorchClassifier
from art.attacks.inference.model_inversion.mi_face import MIFace
# Load the trained model
model = Model()
model.load_state_dict(torch.load('model.pth'))
model.eval() # We put it in eval mode
# Read in out.png
out_img = cv2.imread('out.png', 0).astype(np.float32)
out_img_tensor = torch.tensor(out_img, dtype=torch.float32)
# Start with a an "average" image: a value of 0.5 in all pixels
# input_img = nn.Parameter(torch.ones(17,133)*.5)
input_img = torch.randn_like(out_img_tensor, dtype=torch.float32, requires_grad=True)
# Start with a random image
# input_img = nn.Parameter(torch.rand(17,133))
# I used SGD, AdamW is probably better in practice though
optimizer = torch.optim.SGD([input_img], lr=0.01, momentum=0.9)
# Adadelta requires less tuning of the learning rate
# optimizer = torch.optim.Adadelta([input_img], lr=1.0, rho=0.95, eps=1e-6)
# Number of iterations for optimization (you can tweak this value)
num_iterations = 200000
# Loss function, picked MSE https://stackoverflow.com/questions/66220672/what-should-be-the-loss-function-for-image-reconstruction-while-using-unet-archi
criterion = torch.nn.MSELoss()
for step in range(num_iterations):
# Let's start with a fresh gradient for each iteration
optimizer.zero_grad()
model_output = model(input_img) # model output from the current input image guess
# MSE between model output and target output
loss = criterion(model_output, out_img_tensor) + model_output.abs().sum()*0.008
# Backward pass: Compute gradients
loss.backward()
# Update the input image based on gradients
optimizer.step()
# # Clamp the input image to the range [0, 255]
# input_img.data.clamp_(0, 255)
# Normalize the input image to the range [0, 255]
# input_img.data = (input_img - torch.min(input_img)) / (torch.max(input_img) - torch.min(input_img)) * 255
if step % 10000 == 0:
print(f"Step {step}, Loss: {loss.item()}")
# After optimization, convert the tensor back to an image
recovered_img = input_img.detach().numpy()
# Normalize the recovered image to the range [0, 255]
recovered_img = (recovered_img - np.min(recovered_img)) / (np.max(recovered_img) - np.min(recovered_img)) * 255
# Convert to uint8 and save the recovered image
recovered_img = recovered_img.astype(np.uint8)
cv2.imwrite('recovered_flag.png', recovered_img)And we get

This was super overcomplicated and unneeded. But when I zoomed into the image and squinted a bit (and after a couple guesses), I got the flag, which was ictf{linear_aggression}
The right way to do this
I still didn’t like how fuzzy my recovered flag was, specifically the vertical lines that kept appearing, and I knew there was a better way to do it. But I had other CTF challenges to solve, so I left this one alone and vowed to look for writeups/other solve scripts. Here was one, made by tyler.a.g.
The main thing that helped with this solve script was clamping the input and output at each gradient descent.
import torch
import numpy as np
import cv2
from model import Model
flag = cv2.imread('out.png', 0)
flag_tensor = torch.from_numpy(flag).to(torch.float32)
in_tens =torch.rand(17, 133)
input_tensor = torch.nn.parameter.Parameter(in_tens)
model = Model()
model.load_state_dict(torch.load('model.pth', weights_only=True))
for param in model.parameters():
param.requires_grad_(False)
input_tensor.requires_grad_(True)
optimizer = torch.optim.Adam([input_tensor], lr=1)
for i in range(1, 100000):
optimizer.zero_grad()
out_tensor = model(input_tensor)
loss_fn = torch.nn.MSELoss()
with torch.no_grad():
out_tensor.clamp_(0, 255.0)
loss = loss_fn(out_tensor, flag_tensor)
if i % 10000 == 0:
print(loss.item())
loss.backward()
optimizer.step()
with torch.no_grad():
input_tensor.clamp_(0, 255.0)
out_arr = input_tensor.detach().numpy()
print(out_arr)
cv2.imwrite('flag.png', out_arr)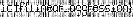
That looks much better. ictf{linear_aggression} was the flag.
Yep, I forgot to clamp tensors. And I overcomplicated it, when I could have just trained a model to guess the initial flag. I had the right idea, but the wrong execution. Even though I sort of solved this, I do think that this is the much better execution.